Меньше нотификаций дают лучшую возвращаемость в долгосроке
Ресерчеры и аналитики из Мордакниги установили, что меньшее количество нотификаций в долгосрочке обеспечивает лучшую возвращаемость в продукт. Хотя поначалу продуктовые метрики и просели.
И выводят два тезиса:
- Результаты эксперимента в короткосроке и долгосроке могут сильно отличаться
- Меньше нотификаций, но более качественных полезнее в долгосрочной перспективе.
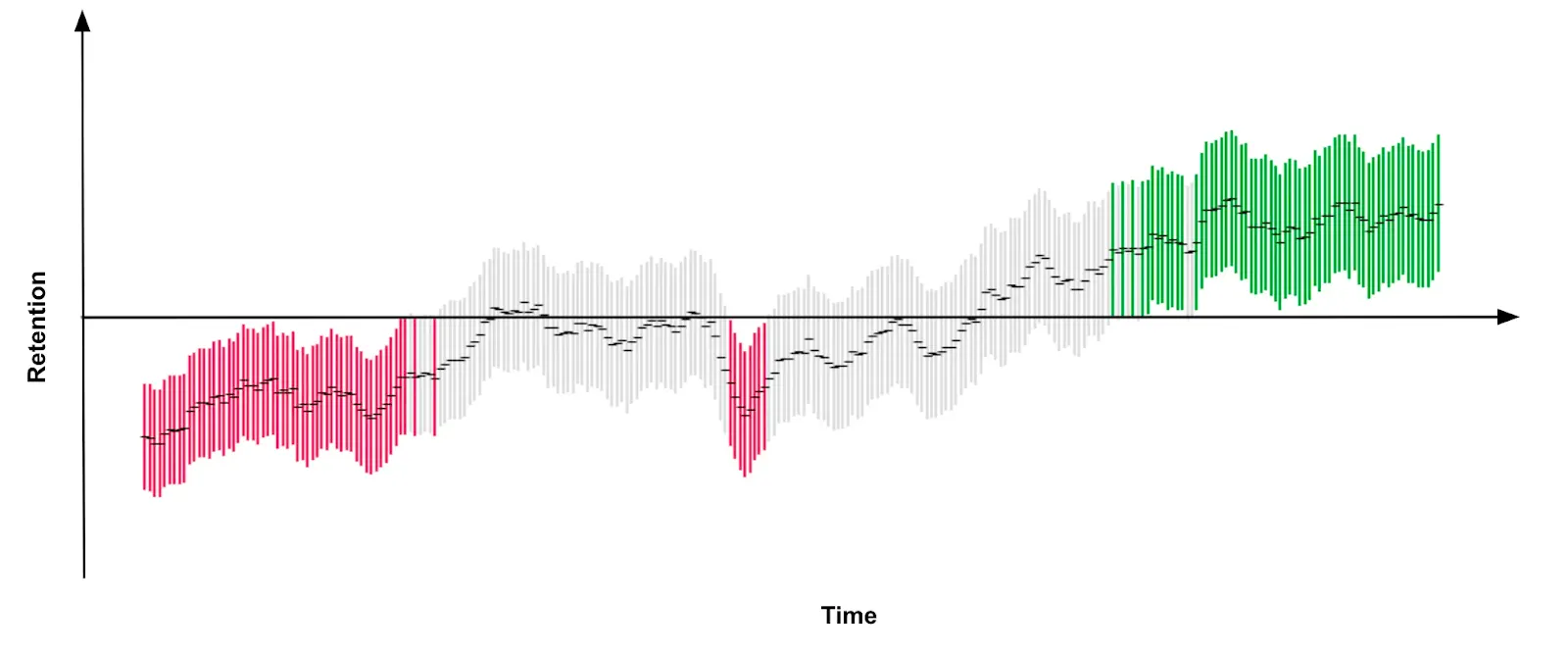
Вроде ясно и очевидно, но представляю сколько организационных и волевых усилий потребовалось для запуска такой инициативы. На масштабах Фейсбука, потеря сессий выливается в гигантские недополученные суммы от показа реклам.
Чтобы этот эксперимент провести и защитить использовали данные из опросов и фактического поведения аудитории.
Еще один хороший пример как смешивание разных типов данных и методов помогают в сложных бизнес-ситуациях.